ADPCM(Adaptive Differential Pulse Code Modulation,自适应差分脉冲编码调制)是一种有损音频压缩算法,它的核心思想是在标准的差分脉冲编码调制(DPCM)基础上引入了步长自适应机制,以更好地应对音频信号的变化,达到更高的压缩率;ADPCM 是一种用于连续波形数据的有损压缩算法,它通过保存相邻波形的变化情况来描述整个波形,从而达到数据压缩的目的。
PCM(Pulse Code Modulation,脉冲编码调制)
PCM 是指将模拟信号抽样、量化、编码变成二进制码元的基本过程,是最常用的语言信号编码技术。
音频数据是连续的模拟型号,通过 PCM 直接将其编码成数值;比如 16-bit PCM 每个采样点占 2 字节,所以一般我们也说 PCM 是最基本的音频数字编码方式。
PCM 实际上就是一个大数组, 数组中每个值, 代表了当前时间点上的模拟量强度, 在播放时在对应的时间点上被转换为模拟量输出(DAC)。
DPCM(差分 PCM)
PCM 保存的是最原始的模数转换结果, 是不压缩的, 数据量比较大, 存储和通讯都会占用很大资源, 需要将数据压缩以减少通信带宽和存储的资源消耗。
DPCM 不再存储每个绝对采样值,而是存储当前采样值和前一个采样值的“差值”。优点是差值的变化通常更小,可以用更少的位数表示(比如用 4 或 8 位)。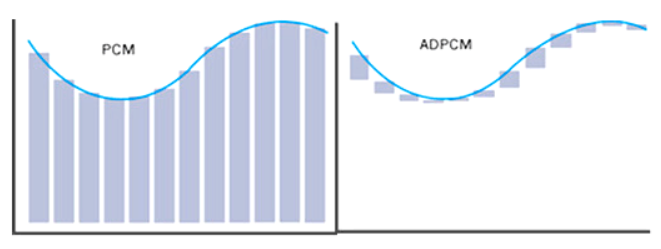
将音频 PCM 的数组展开观察可以看到,数据值与相邻的值通常是比较连续的, 不会突然很高或者突然很低, 两点之间差值不会太大,,所以这个差值可以用很少的几个位(比如 4bit)表示。这样只需要知道起始点的值和每个点的差值,就可以还原得到原来的序列。记录的差值序列就是DPCM数据。这样数据量会小很多。
以 8K 采样率为例,如果量化精度为 16bit,则 1 秒的数据量为 8000 * 16bit = 128kb, 如果用 4bit 的表示差值, 则 1 秒的 PCM 数据转成 DPCM 只需要约 32kb。
ADPCM(自适应差分 PCM)
DPCM 存在一个问题,音频信号虽然比较连续性,但是存在差值较大的情况,例如差值超过 4bit 表示的范围(-15, 15) 就无法很好还原原来的 PCM 序列,这时候如果增大差值宽度,例如用 6bit,8bit 表示,可以减小这个问题,但数据量也增大了。
ADPCM 的出发点就是解决 DPCM 的差值宽度问题,通过定义一个差值表(例如 IMA ADPCM 中使用 89个固定差值,取值从7到32767),将差值的范围放宽到 16bit,此时差值在数组中的编号只需要 6bit 就可以表示(0 - 88),再进一步只记录编号的变化值,就将变化量压缩到了 4bit。
在 DPCM 基础上,ADPCM 加入了步长(step size)自适应调整机制,来根据信号波动调整编码的精度,提升压缩效率和音质。
核心特点:
- 差分编码:编码的是当前样本与预测样本之间的差值(而非原始样本值),减少数据冗余。
- 自适应步长:根据信号变化动态调整量化步长,以适应音频信号的动态范围。
- 低计算复杂度:适合资源受限的嵌入式系统。
- 固定压缩率:每个样本编码为 4 位,易于硬件实现。
IMA ADPCM
IMA ADPCM(Interactive Multimedia Association Adaptive Differential PCM) 是一种由 IMA 协会提出的标准化的 ADPCM 算法,它每个采样点使用 4 位(4-bit) 数据来表示压缩后的差值(delta)。
IMA ADPCM 编码格式
IMA ADPCM 是把原始的 16bit PCM 数据压缩成 4bit 的编码值。在 C 语言里,没有办法单独定义“4-bit”变量。最小单位是 8bit(1个字节),所以我们用 uint8_t 来存储两个 4-bit 的 ADPCM 编码值。
对于IMA ADPCM, 还需要了解两个码表, 一个是差值步长码表, 一个是差值步长下标变化量码表
- 差值步长码表: 下标从 0 到 88,共 89 个值,从小到大,非均匀分布,下标越大,值之间的间隔越大。
- 差值步长下标变化量码表: 下标从 -7 到 7, ADPCM 队列中每个值可以通过这个直接查表得到下一个值的差值步长的下标变化量, 进而得到下一个值的差值步长。 值在 [-3, 3] 之间的, 变化都是 -1, 也就是差值步长变小, 在 [-4,-7] 和 [4,7] 的, 变化是 2, 4, 6, 8 可以看到对于 -7 和 7, 差值步长会快速增大。
1 | static int ADPCM_stepsizeTable[89] = { // 差值步长码表 |
IMA ADPCM 格式说明
例如一个 IMA ADPCM 编码值为 0x05, 对应二进制 0101, 其中最高位为 0, 代表变化为正, 输出值是在前一个值上叠加; 低三位为 5, 代表差值步长下标变化量为 +4(对应 ADCPCM_indexTable[5]),也就是差值步长变大了, 另外三位的每一位分别代表对应实际差值的差值步长的倍数, 参与了差值的计算。
| bit位 | 值 | 含义 |
|---|---|---|
| 4 | 0 | 最高位(Sign Bit):表示差值正负(0 = 正,1 = 负)。 |
| 3 | 1 | 低三位(Magnitude Bits):表示量化级别,权重 4,贡献 1 倍步长,调整索引。 |
| 2 | 0 | 权重 2,贡献 0.5 倍步长,参与差值计算和索引调整。 |
| 1 | 1 | 权重 1,贡献 0.25 倍步长,参与差值计算和索引调整。 |
上会产生 1 + 0 + 0.25 = 1.25 倍的差值步长,加上固定的 1/8 步长, 就是说这一步产生的输出 = 前一步数值 + 当前差值步长 * 1.375,这个值会作为下一步的数值,同时下一步的差值步长下标 +4,也就是下一个值的计算中用到的差值步长增大了。
编码
1 | // IMA ADPCM 编码器:将 16 位 PCM 音频压缩为 4 位 ADPCM,压缩比 4:1 |
解码
解码就是将 ADPCM 数组中的每个 4bit 数值,还原回编码过程中的每个 presample 值,
1 | // IMA ADPCM 解码器:将 4 位 ADPCM 音频解码为 16 位 PCM,压缩比 4:1 |